Some common problems in localizing applications are:
- Non-localizable text A program may have hard-coded text in the program source itself, or parts of messages may come from other non-localized sources (such as from a database), or there could be bugs in finding and using localized messages. The accents pseudolocalization method helps identify these problems by replacing US-ASCII characters with accented or otherwise modified versions, while still remaining readable. That way, if you see unaccented text, you know that text will not be localized for real locales either.
- Combining separately translated sentences or paragraphs A program may “piece together” complete sentences/paragraphs from smaller translated strings. This is a problem since some locales may require that parts of the sentence/paragraph be reordered, or the translation may depend on the context of what else appears in the sentence. The brackets pseudolocalization method adds [ and ] around each translated string to clearly show translation boundaries. If you see a sentence/paragraph broken up into multiple bracketed pieces, you know it is likely to be impossible to translate well for some locales.
- User interface elements don’t give sufficient space for translated text Some languages, such as German, frequently have translations that are much longer than the original message. If the user interface does not allow sufficient room for such languages, parts of it may appear wrapped, truncated, or have unsightly scrollbars in such locales. If the developer only tests with the original language, the developer may not discover these problems until late in the development cycle. The expander pseudolocalization method addresses this by making all the strings longer. Looking at the resulting pseudolocale will allow the developer to find such problems long before real translations are available and without requiring knowledge of other languages.
- Improperly “mirrored” user interfaces in right-to-left locales Some languages like Arabic and Hebrew are written right-to-left. A user interface in a right-to-left (RTL) language needs to be laid out in a mirror image of a left-to-right layout. The only way to tell if this has been done properly is to try the user interface in an RTL locale. However, using a real RTL language is problematic both because translations are unlikely to be available until late in the development cycle and because few developers might be able to read any RTL languages.
Using untranslated LTR messages in an RTL user interface is problematic because it masks real problems and creates apparent problems where none actually exist. Just setting dir=”rtl” on the HTML element of an otherwise-English UI produces something like this:
Note how some of the punctuation is misplaced and not mirrored, the radio buttons are a mess, and the order of the menu items isn’t mirrored. None of these happen to be real problems — they will disappear when the English strings are replaced with real translations.
The solution is the fakebidi pseudolocalization method, which takes the original source text and adds Unicode characters to it to make it behave just like real RTL text while remaining readable (though backwards).
We find the most useful combinations of pseudolocalization methods to be accents/expander/brackets for finding general internationalization problems, and fakebidi for finding RTL-related problems. We use BCP47 variant subtags to identify locale names that get pseudolocalized translations: psaccent (as in en-psaccent) gets the accents/expander/brackets pseudolocalization, and psbidi (as in ar-psbidi) gets fakebidi. Note that for psbidi, using a real RTL language subtag is recommended since that will trigger RTL handling in most libraries/frameworks without any modifications. We hope to get these variant tags accepted as standard.
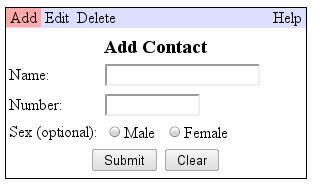
We have taken the sample application from above and run its translatable text through psaccent and psbidi pseudolocalization. Now take a look and see how much more easily internationalization problems can be identified:
 Note that three problems have been revealed by the use of psaccent:
Note that three problems have been revealed by the use of psaccent:
- the space provided is insufficient for longer translations
- “Add Contact” is split across two messages making it difficult to translate correctly
- the button text has not been translated
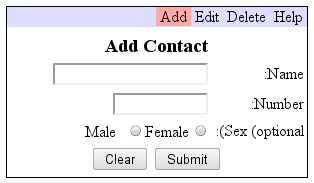
We can fix those problems, then check for Bidi problems by using psbidi:
 Notice this doesn’t introduce problems that aren’t there like the earlier example, but it does show that the Help menu item does not float to the left side of the window as it should.
Notice this doesn’t introduce problems that aren’t there like the earlier example, but it does show that the Help menu item does not float to the left side of the window as it should.
Initially, this is just a library for use with other tools. We plan to write a command-line tool for taking message sources and producing fake translations of them. In addition, we are in the process of integrating this library with GWT, so GWT users can take advantage of it just by inheriting one module.
In summary, pseudolocalization is useful for finding internationalization problems early in the development process and enabling the developer to fix them before wasting money on translations that may have to be changed to fix the problems anyway. We hope you will use this library to help make your application usable by more people, and we welcome contributions and discussions at https://groups.google.com/forum/#!forum/pseudolocalization-tool.