Today we launched Google Art Project in collaboration with 17 of the world’s most renowned museums. Google Art Project is built on top of App Engine and lets you take virtual tours of famous museums using internal Street View technology, view high resolution images of famous art work, and create personal virtual artwork collections.
When Art Project started development several months ago, the team built the application using Java and the Master/Slave Datastore. However, as their launch date approached, we released the new High Replication Datastore configuration and, with a scheduled maintenance period so soon after the site’s launch, they decided to switch over to the High Replication Datastore.
Before switching, they ran a load test to set a performance baseline for comparison after the application’s data was migrated. Now that the application has launched, we wanted to share the results of the test with you as an example of what to expect after a switch to the High Replication Datastore. Below are the mean numbers for latency of different parts of the site.
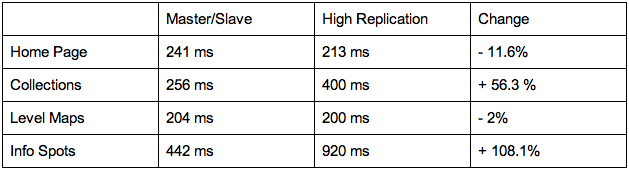
Here’s a description of what each page does behind the scenes:
Homepage: This is the landing page that just serves a static webpage for site navigation. Since this page does not pull information from the datastore, the latency is stable.
Collections: Art Project lets users create individual museum collections. These load tests specifically targeted adding and deleting paintings from a user’s personal collection, as well as rendering those collections. We notice the slightly increased latency from saving and deleting entities in the datastore.
Level Maps: These pages simply performed get() calls on the datastore using entity keys. Latency on these pages is consistent across instances.
Info Spots: This handler performs the most data intensive calculations of all of the handlers. It calculates all line of sight interest points for a user’s map position in a museum gallery room, and saves the points of interest to the datastore for that location. The good news is, this calculation doesn’t have to happen for every user. Once this data has been calculated for a given spot, it can re-used for other visitors to the site.
As you can see, while there was some increased latency when switching to the High Replication datastore, the site latency is still very low. And the migration required no major code changes and no modification to the datastore structure between the two load tests.
For more information about the High Replication Datastore, see the Datastore documentation. The next scheduled maintenance period for the Master/Slave datastore is February 7th, 2011 from 5pm – 6pm PST. The High Replication datastore and Google Art Project will not need to be read-only during the by this period. On the High Replication Datastore, your application won’t need to be either.
