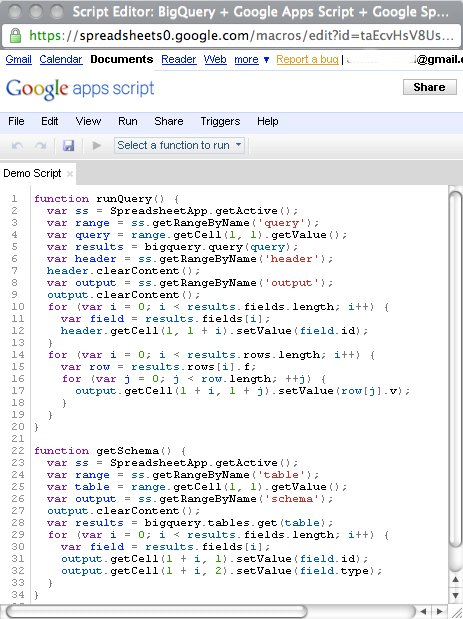
When App Engine launched over two years ago, we offered a Datastore that was designed for quick, strongly consistent reads. It was based on a Master/Slave replication topology, designed for fast writes while still allowing applications to see data immediately after it was written. For the past six months, as you are probably aware, we’ve been struggling with some reliability issues with the App Engine Datastore. Over the course of the past few months, we’ve made major strides in fixing these issues. However, our experience with these issues has made us rethink some of our design assumptions. As we promised you in some of our outage reports earlier this year, we wanted to give you a more fundamental solution to the problem.
Today I’m proud to announce the availability of a new Datastore configuration option, the High Replication Datastore. The High Replication Datastore provides the highest level of availability for your reads and writes, at the cost of increased latency for writes and changes in consistency guarantees in the API. The High Replication Datastore increases the number of data centers that maintain replicas of your data by using the Paxos algorithm to synchronize that data across datacenters in real time. One of the most significant benefits is that all functionality of your application will remain fully available during planned maintenance periods, as well as during most unplanned infrastructure issues. A more detailed comparison between these two options is available in our documentation.
From now on, when creating a new application, you will be able to select the Datastore configuration for your application. While the current Datastore configuration default remains Master/Slave, this may change in the future.

Datastore configuration options when creating an app.
The datastore configuration option can not be changed once an application is created, and all existing applications today are using the Master/Slave configuration. To help existing apps migrate their data to an app using the High Replication Datastore, we are providing some migration tools to assist you. First, we have introduced an option in the Admin Console that allows an application to serve in read-only mode so that the data may be reliably copied between apps. Secondly, we are providing a migration tool with the Python SDK that allows you to copy from one app to another. Directions on how to use this tool for Python and Java apps is documented here.
Now, a word on pricing: Because the amount of data replication significantly increases with the High Replication datastore, the price of this datastore configuration is different. But because we believe that this new configuration offers a significantly improved experience for some applications, we wanted to make it available to you as soon as possible, even though we haven’t finalized the pricing details. Thus, we are releasing the High Replication Datastore with introductory pricing of 3x that of the Master/Slave Datastore until the end of July 2011. After July, we expect that pricing of this feature will change. We’ll let you know more about the pricing details as soon as they are available, and remember, you are always protected when pricing changes occur by our Terms of Service. Due to the higher cost, we thus recommend the High Replication Datastore primarily for those developers building critical applications on App Engine who want the highest possible level of availability for their application.
Thank you, everyone, for all the work you’ve put into building applications on App Engine for the past two years. We’re excited to have High Replication Datastore as the first of many exciting launches in the new year, and hope you’re excited about the other things we’ve got in store for App Engine in 2011.