If you use Google Maps in English, you might notice we’ve expanded our coverage of translated labels. Previously, map labels would display both transliterated and local names for many places. Using a single language can help users by making the map easier to read. For example, the label for Moscow on our English maps used to display as “Moskva (Москва)”. This was great for learning how places are named in other languages but also resulted in twice as many labels on the map.
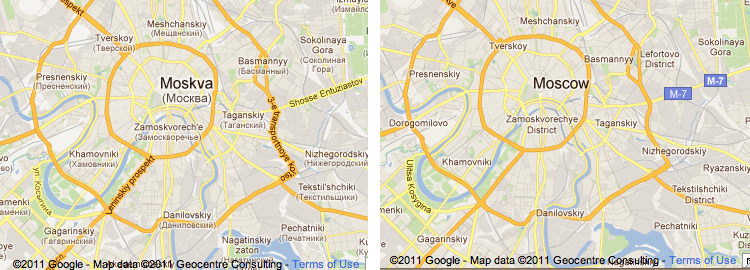
Below are some nice examples of improvements in Europe and China. Many Italian cities are now labeled with translated English names and China now has province names in English.
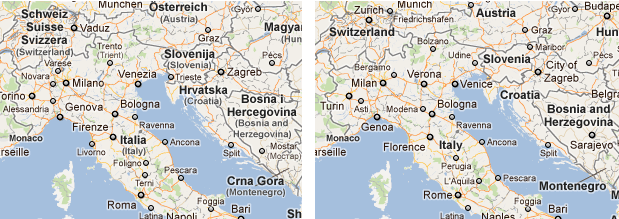

We realize it can be useful to see local language labels for learning place names so we’ve kept the option available. If you prefer to see local language labels, you can still do so by unchecking English in the maps menu (move your cursor to the ‘layers’ menu in upper right corner of the map and un-check English when the menu drops down). This is the same for other single-languages which Maps supports. Also note that we may still show multiple labels in some places where there are two local languages or when place names are disputed.
In total, Google now has single-language Maps for 5 major languages – Chinese, Japanese, Korean, Russian, and now English with more languages on their way. We hope this change makes it easier to browse, explore and discover the world around you.
GoogleLatLong