I have just heard the news about flash flooding in Toowoomba and Lockyer Valley, Queensland. In this latest incident eight people died and so far over 70 are missing. Death toll is expected to rise. My heart goes out to all that have lost loved ones in this tragedy.
The overall death toll from floods in NSW and QLD in November 2010 to January 2011 is much higher but statistics are not readily available. As usual, after the clean up is finished questions will be asked: “Was this tragedy preventable?”. Then millions will be poured into a solution “…to prepare us for the next time”, as was the case with all previous disasters. So now Australia has a few hundred million dollar tsunami detection and early warning system to prepare us for another one-in-100-years event. As a result of Victorian bushfires we also have a multi million dollar monitoring and alert system (including phone messaging alerts) for bushfires. Flood warning system will be the next…
Why it always takes a tragedy to motivate governments to do something to improve safety of its citizens? The money is then no objective to find a better approach/ solution… Why can’t there be a proactive rather than reactive approach to disaster mitigation?
What I am about to say is not intended a as a criticism of authorities, rather just a statement of facts. Yes, it is obvious that a bit more proactive approach would save lives but the reality is that it is very difficult for authorities, whether State or Federal to do things proactively. Most often then not, priorities of the day take precedence (just read news headlines and it will become clear what this priority is on any given day). It takes lots of resources and time to get major projects off the ground, then administer them towards a particular outcome. Therefore, there must be a catalyst, a disaster if you like, to shake things up and get politicians to “find” those millions to put policies in place to prevent another similar tragedy.
Don’t get me wrong, not that there are no continuous improvements to current disaster mitigation programs, but still, it takes a disaster to focus the attention of decision makers on things that “should have been done in the first place”… Again, the reality is that Departments and agencies can only work on projects within their allocated range of responsibilities and currently allocated tasks, and money. All in all, it is very difficult for pubic service institutions operating in our existing governance structures to do things proactively, without aligning to specific agendas of the government of the day…
So, who else is there to look after the interests of individual citizens? I believe that community at large should accept part of the responsibility for looking after its own affairs. Even without huge financial resources public initiatives can make enormous impact. And with respect to prevention of disasters, communities can assist or complement things put in place with government funded programs. But there have to be a widespread commitment for things to work…
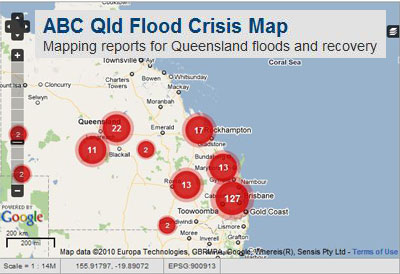
Just consider a few examples of community lead projects in GIS arena like, for example, OpenStreetMap community response to 2010 Haiti earthquake or Ushahidi community engagement after Haiti and Chile earthquakes. Australia has its own suite of natural disaster focused applications, either community based or maintained by enthusiasts. For example, ABC has just released ABC Qld Flood Crisis Map, built on Ushahidi platform, for crowdsourcing reports on Queensland floods and recovery operations. BushfireConnect is another community lead Ushahidi deployment for corwdsourcing reports on bushfires. Ushahidi platform can be configures to send SMS alerts to registered users. My own Hazards Monitor is yet another example of a private initiative to monitor and report on natural disasters.
There is also The Australian Early Warning Network that republishes Bureau of Meteorology information and sends emergency alerts to mobile phones, home phones, pagers and via SMS or e-mail. It is maintained by a private company.

Lucky for Australia, the disasters are few and far between. But this is exactly what makes proactive investment in natural hazards monitoring and disaster response systems, whether government sponsored or community lead, so difficult. Interest in those systems diminishes as quickly as the tragedy disappears from news headlines. It is so hard to keep politicians and community engaged and supportive for the initiatives when there is no threat present. So, in the end, it is always up to a bunch of committed individuals who work on solutions proactively, and despite all the odds, in anticipation that their effort one day may save a life. Sad reality… So, paraphrasing JF Kennedy: “…ask not what your country can do for you – ask what you can do for your country…” to limit the outcome of natural disasters in the future!

